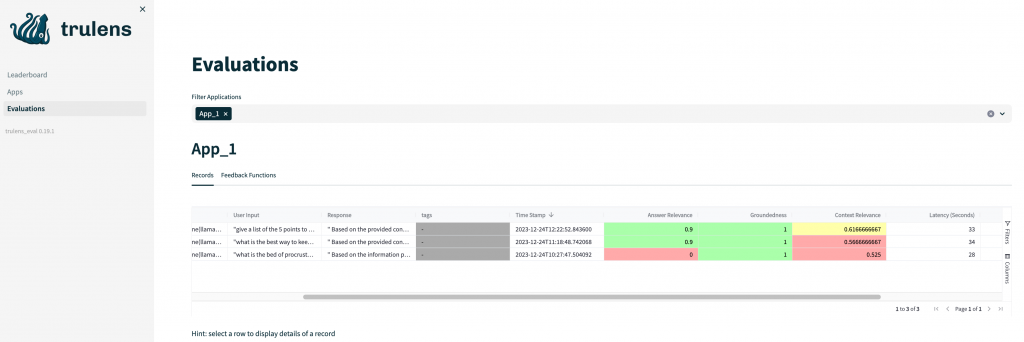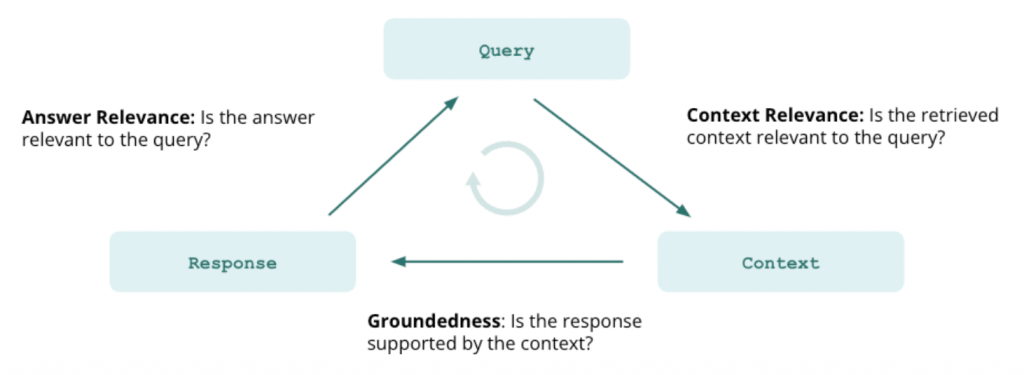
What Trulens library is doing under the hood is using LLM completions to make the evaluations. For each metric a feedback function is defined. These feedback functions return a score for the metric that indicates how good the metric is for that question being asked to the RAG. This means, that if your machine is not fast executing the LLM completions, then the evaluations are going to take a very long time. For example: for an Apple Sillicon M1 Pro a RAG query can take up to 30 seconds where the majority of the time is spent on the LLM completion. If we take into account that each query evaluation will take at least 3 completions, this means that the overall evaluation time will be at least 5 minutes.
The code shows how each of the metrics have to be specified, each with its own Trulens data structure. It’s important to notice that while for the query engine and its completions we use the Ollama library directly, to make the completions for the evaluations we use the LiteLLM library. This library is the one that has the integration with Trulens to use the Ollama. Also, bear in mind that in both cases we are specifying the LLM to be in a remote machine. In my case, I was using an M1 Pro chip, but in the ideal case one would be using a GPU or just paying for the completions to some API provider such as OpenAI, Cohere, Gradient, etc.