Architecture design and implementation of a Big Data system in AWS for processing daily electricity consumptions in Red Eléctrica de España. This involved AWS Glue, EMR, Lambda, Pyspark, Zeppelin, Redshift, Spectrum, SFTP and S3.
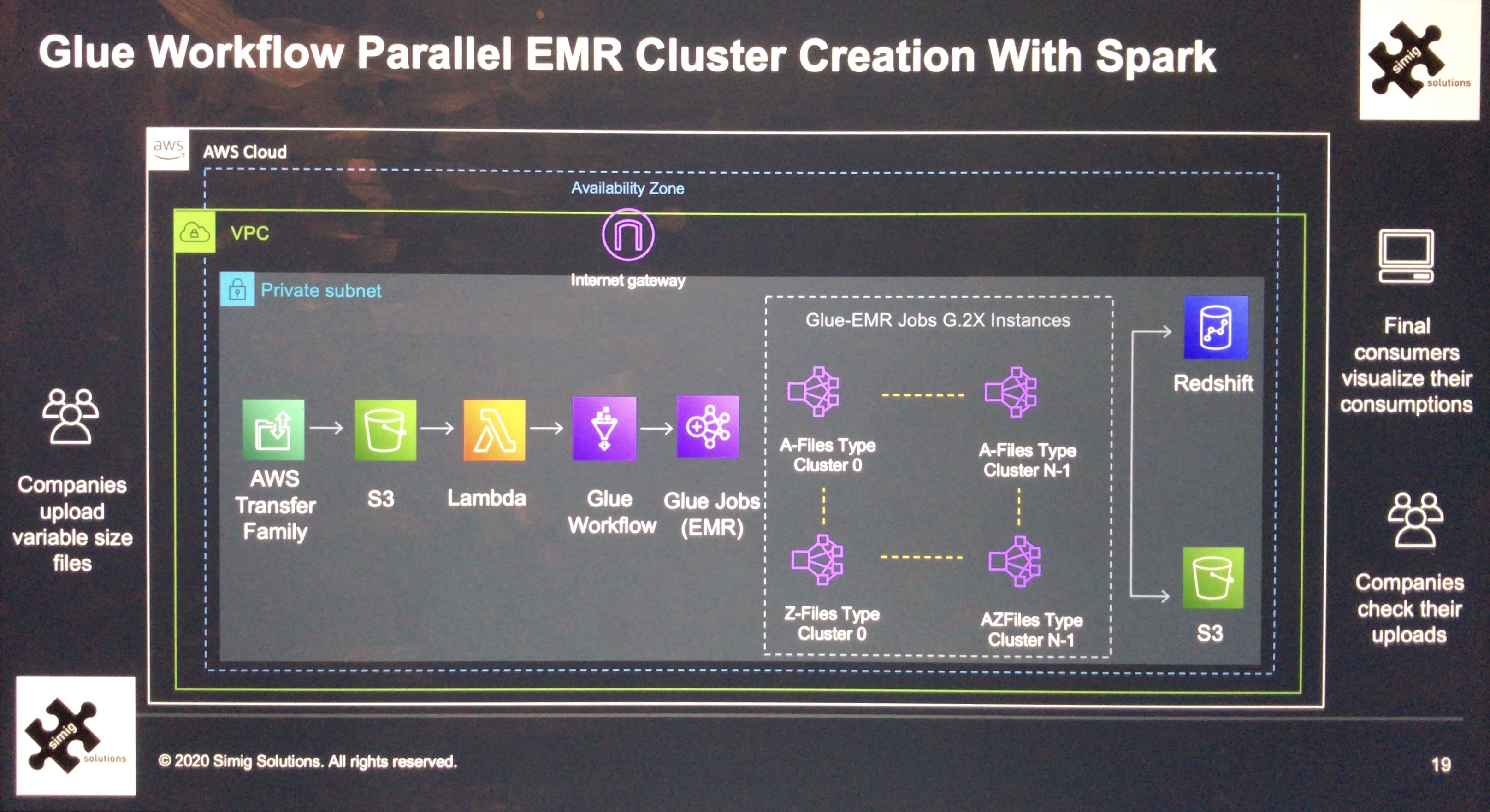
Th below picture shows the data pipeline of the ETL. In this case I designed a transient ETL to economise in the budged of the client by having the machines working when there was workload. To achieve this I I used AWS Glue as the technology to rise clusters on demand with a very short period of time (less than 5 minutes). This allows to process all the data when this one arrives. In this case, data were arriving during peak times in the form of small files but also around 5% of the files could be in the order of GBs. This required a great flexibility in the way of processing, which was solved by spanning multiple Glue-EMR clusters in parallel to accelerate the files ingestion being the load unpredictable and in the form of peaks.
Data Pipeline